
C言語において、文字列は「文字の配列」であり、その末尾には必ずヌル文字(\0)が存在します。
この記事では、文字列の内部構造からポインタ操作、そして本格的な探索アルゴリズムまで、全12個のサンプルプログラムをステップバイステップで解説します。
文字列の内部構造(ビット表示)
【List 8-1】文字列をダンプ解析する(str_dump.c)
文字列がメモリ上でどのように保持されているか、2進数と16進数で確認します。
ソースコード
#include<stdio.h>
#include<limits.h>
void str_dump(const char *s){
do{
int i;
printf("%c %0*X ",*s,(CHAR_BIT+3)/4,*s);
for(i=CHAR_BIT-1;i>=0;i--)
putchar(((*s>>i)&1U)?'1':'0');
putchar('\n');
}while (*s++ != '\0');
}
int main(void){
str_dump("STRING");
return 0;
}実行結果
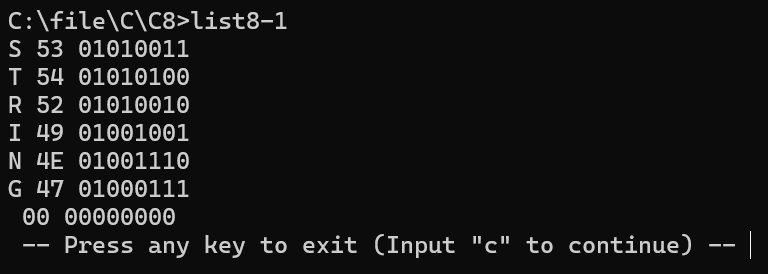
解説: 文字列の末尾でループが止まるのは、\0(全ビットが0)を検知するからです。C言語の文字列操作のすべての基本がここにあります。
文字列の初期化(配列とポインタ)
【List 8-2】配列による1文字ずつの格納(str_ary1.c)
ソースコード
#include<stdio.h>
int main(void)
{
char st[10];
st[0]='A';
st[1]='B';
st[2]='C';
st[3]='D';
st[4]='\0';
printf("文字列stには\"%s\"が格納されています。\n",st);
return 0;
}実行結果

解説: 手動で \0 を代入する例です。これがないと、printf はどこで表示を止めていいか分からず、メモリ上のゴミを表示し続けてしまいます。
【List 8-3】配列による初期化の簡略化(str_ary2.c)
ソースコード
#include<stdio.h>
int main(void)
{
char st1[10]={'A','B','C','D'};
char st2[10]="ABCD";
printf("文字列stには\"%s\"が格納されています。\n",st1);
printf("文字列stには\"%s\"が格納されています。\n",st2);
return 0;
}実行結果

解説: ダブルクォーテーションを使うと、末尾の \0 を意識せずに初期化できるため、通常はこちらを使います。
【List 8-4】ポインタによる文字列の参照(str_ptr.c)
ソースコード
#include<stdio.h>
int main(void)
{
char *pt="12345";
printf("ポインタptには\"%s\"が格納されています。\n",pt);
return 0;
}
実行結果

解説: 配列との大きな違いは、pt は「文字列が格納されている場所」を指している点です。
ポインタ操作の極意
【List 8-5】ポインタの値を交換する(swap_ptr.c)
文字列そのものをコピーするのではなく、「指し示す先(アドレス)」だけを入れ替える効率的な手法です。
ソースコード
#include<stdio.h>
void swap_ptr(char **x, char **y)
{
char *tmp=*x;
*x=*y;
*y=tmp;
}
int main(void)
{
char *s1="ABCD";
char *s2="EFGH";
printf("ポインタs1は\"%s\"を指しています。\n",s1);
printf("ポインタs2は\"%s\"を指しています。\n",s2);
printf("\nポインタs1の値は %p です。\n",s1);
printf("ポインタs2の値は %p です。\n",s2);
printf("\nポインタ&s1の値は %p です。\n",&s1);
printf("ポインタ&s2の値は %p です。\n",&s2);
swap_ptr(&s1,&s2);
puts("\nポインタs1とs2の値を交換しました。\n");
printf("ポインタs1は\"%s\"を指しています。\n",s1);
printf("ポインタs2は\"%s\"を指しています。\n",s2);
printf("\n");
return 0;
}
実行結果
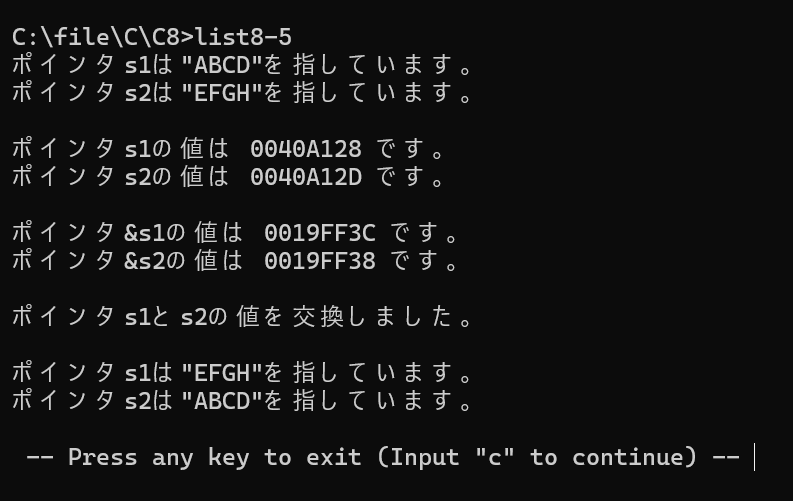
解説: ポインタ変数の中身を書き換えるため、ダブルポインタ(**)を使用します。これが理解できればC言語中級者への一歩です。
文字列の長さを計る3つの手法
文字列の長さを求める strlen 関数を自作してみましょう。
- 【List 8-6】手法1:配列の添字を利用
while (s[len]) len++;とし、添字を1ずつ増やして数えます。 - 【List 8-7】手法2:ポインタのインクリメント
while (*s++) len++;とし、ポインタ自体を動かしながらカウントします。 - 【List 8-8】手法3:アドレスの差分を計算
const char *p = s;で開始位置を保存し、末尾まで進んだsからpを引く(s - p)ことで一気に長さを算出します。
ソースコード(str_len.c)
#include<stdio.h>
int str_len1(const char *s)
{
int len=0;
while (s[len])
len++;
return len;
}
int str_len2(const char *s)
{
int len=0;
while(*s++)
len++;
return len;
}
int str_len3(const char *s)
{
const char *p=s;
while (*s)
s++;
return s-p;
}
int main(void)
{
char str[256];
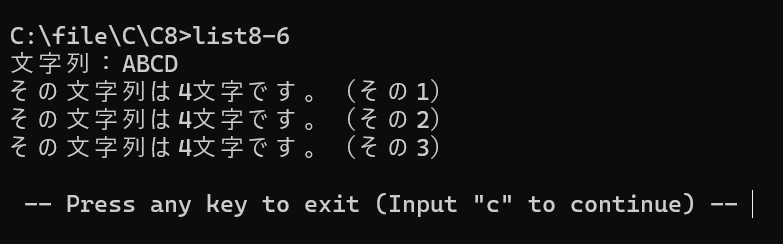
printf("文字列:");
scanf("%s",str,sizeof(str));
printf("その文字列は%d文字です。(その1)\n",str_len1(str));
printf("その文字列は%d文字です。(その2)\n",str_len2(str));
printf("その文字列は%d文字です。(その3)\n",str_len3(str));
printf("\n");
return 0;
}実行結果
文字・文字列の検索と比較
【List 8-9】文字の探索(str_chr.c)
文字列の中から、指定した1文字がどこにあるかを探します。見つからない場合は -1 を返します。
ソースコード
#include<stdio.h>
int str_chr(const char *s,int c)
{
int i=0;
c=(char)c;
while (s[i]!=c)
{
if(s[i]=='\0')
return -1;
i++;
}
return i;
}
int main(void)
{
char str[64];
char tmp[64];
int ch;
int idx;
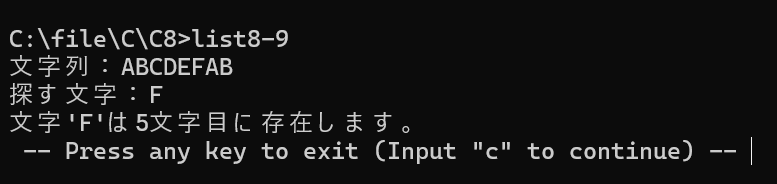
printf("文字列:");
scanf("%s",str);
printf("探す文字:");
scanf("%s",tmp);
ch=tmp[0];
if((idx=str_chr(str,ch))==-1)
printf("文字'%c'は文字列中に存在しません。\n",ch);
else
printf("文字'%c'は%d文字目に存在します。\n",ch,idx);
return 0;
}実行結果
【List 8-10】文字列の比較(str_cmp.c)
2つの文字列が同一かどうかを判定します。
ソースコード
#include<stdio.h>
#include<string.h>
int str_cmp(const char *s1,const char *s2)
{
while (*s1==*s2)
{
if(*s1=='\0')
return 0;
s1++;
s2++;
}
return (unsigned char)*s1-(unsigned char)*s2;
}
int main(void)
{
char st[128];
puts("\"ABCD\"との文字列を比較します");
puts("\"XXXX\"で終了します");
while (1)
{
printf("文字列st:");
scanf("%s",st,sizeof(st));
if(strcmp("XXXX",st)==0)
break;
printf("str_cmp(\"ABCD\",st)=%d\n",str_cmp("ABCD",st));
}
return 0;
}実行結果
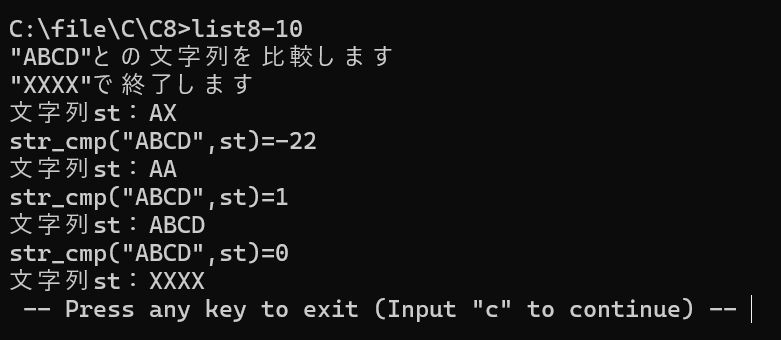
解説: 戻り値が 0 なら一致。不一致なら、その差分を返します。比較の際は unsigned char にキャストするのが鉄則です。
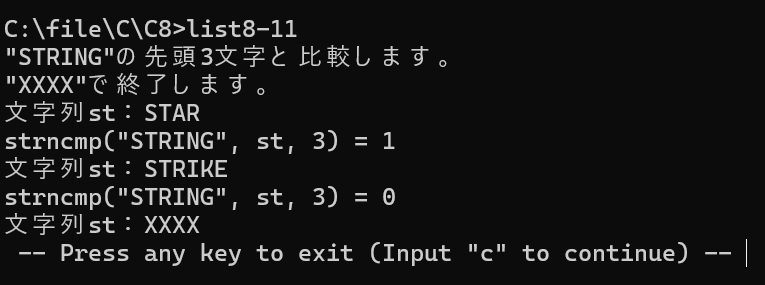
【List 8-11】先頭n文字の比較(strncmp_test.c)
strncmp 関数を使い、文字列の先頭数文字だけを比較します。
ソースコード
#include<stdio.h>
#include<string.h>
/* 文字列の比較(strncmp関数)*/
#include <stdio.h>
#include <string.h>
int main(void)
{
char st[128];
puts("\"STRING\"の先頭3文字と比較します。");
puts("\"XXXX\"で終了します。");
while (1) {
printf("文字列st:");
scanf("%s", st);
if (strncmp("XXXX", st, 3) == 0)
break;
printf("strncmp(\"STRING\", st, 3) = %d\n", strncmp("STRING", st, 3));
}
return 0;
}実行結果
本格アルゴリズム:文字列探索(力まかせ法)
【List 8-12】力まかせ法(bf_match.c)
長いテキストから、特定の文字列(パターン)を探し出すアルゴリズムです。
ソースコード
#include <stdio.h>
int bf_match(const char txt[], const char pat[])
{
int pt = 0; /* txtをなぞるカーソル */
int pp = 0; /* patをなぞるカーソル */
while (txt[pt] != '\0' && pat[pp] != '\0') {
if (txt[pt] == pat[pp]) {
pt++;
pp++;
} else {
pt = pt - pp + 1;
pp = 0;
}
}
if (pat[pp] == '\0')
return pt - pp;
return -1;
}
int main(void)
{
int idx;
char s1[256]; /* テキスト */
char s2[256]; /* パターン */
puts("力まかせ法");
printf("テキスト:");
scanf("%s", s1);
printf("パターン:");
scanf("%s", s2);
idx = bf_match(s1, s2);
if (idx == -1)
puts("テキスト中にパターンは存在しません。");
else
printf("%d文字目にマッチします。\n", idx + 1);
return 0;
}実行結果
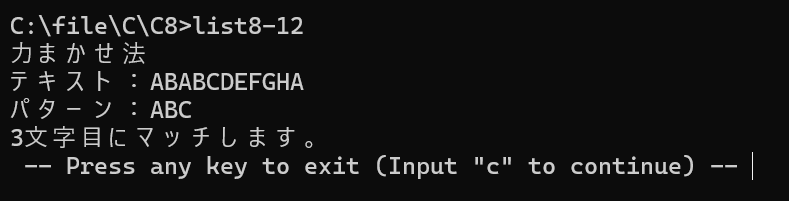
核心: 一致しなかった際、テキスト側のカーソルを「一致し始めた位置の次」まで戻す処理がこのアルゴリズムの肝です。
まとめ:C言語の文字列操作 3つの極意
List 8-1から8-12まで、多くのコードを見てきましたが、重要なポイントは以下の3点に集約されます。
- 文字列の終端は必ず
\0(ヌル文字) すべてのループ処理や標準関数は、この\0を目印に動作しています。List 8-1でのバイナリ確認はその本質を理解するための第一歩です。 - 配列とポインタの使い分け データの箱を確保する「配列」と、アドレスを指し示す「ポインタ」。List 8-5の交換処理(swap)のように、ポインタを操れるようになるとC言語の自由度が飛躍的に上がります。
- アルゴリズムの基礎「力まかせ法」 List 8-12で学んだ探索ロジックは、すべてのアルゴリズムの原点です。「不一致なら一歩戻ってやり直す」という仕組みを理解することで、より高度なBM法やKMP法への道が開けます。



{kind=link}
{kind=link}
コメント